Runtime Schema Based Documents
When it comes to handle document-like data the employment of a
document-oriented database could be a very valid option.
However, if you also value to maintain all your application’s data in a
single data storage system that keeps traditional table based records
closely integrated with document-like data of more volatile structure
the schema based document processing feature provided by the
Tlabs.Data library could be your choice.
Structure of Document Data
Document Data in general is structured into two parts:
A predefined document header that is technically treated like any other data entity with a fixed set of fields which are accessible for sorting, searching and manipulation through static business logic (program code). The fields of a document header are typically designed to serve as an overview summary of the entire document.
A customizable body part consisting of an arbitrary list of fields that have been defined with a so called schema. (The particular name of the schema used to define the fields of a body is stored in a dedicated field in the document header.)
NOTE:
Since the program code of an application cannot know about the definition of these custom fields in advance, access to these custom fields needs to be related to dynamic context:
De-/Serialization of document data from public API’s is fully supported (including data import/export).
Usage of custom forms in the UI defined with the document schema (see below).
Dynamically defined formula expressions have full type safe access to custom fields.
The Document Schema is a dynamic definition of the actual layout of a document. Schemas are dynamic because they can be created and updated during runtime by uploading the schema definition file(s) into the running application instance using specific APIs. (To create and upload such schema definition file(s) a specialized tool like the Tlabs.Meta.Bench is typically used.)
Schemas are identified with a unique schema-id (Sid) that looks like
RETAIL-PROD:1. It is consisting of three parts:
The main schema name (like
RETAIL)A (optional) schema sub-type (like
PROD)
It is recommended to structure schema names using common sub-types likePROD(product master),ITM(line-item),PROF(client promotion profile),PAR(promo. program parameters)Version number
For each Schema a complete version history can be maintained. Each document entity has a field in its header part containing the schema-id (Sid) of the actual Schema to be used for accessing the fields in the custom body part of the document. This allows for documents of the same entity type to support contents created with different Schema and Schema-Versions!
Document Summary
In general the summary fields of the header part of a document should be
assumed as not being directly writable e.g. via data import or update
APIs. Their contents are defined in an indirect way.
Whenever a document gets updated (or created) the summary fields of its
header part are composed following this rules:
If the body part of the document (that is being setup in the first place) contains a field with the same name as a summary field of the header part this body field value gets promoted to the header field of same name.
NOTE: The value of the body field could be composed with an expression formula from one or even multiple other fields of the body (see computed field values). This allows for flexible mapping from body fields to the summary field.As a fall back (if no matching body field exists) the current value of the header field (optionally specified from some API input values) is taken.
Schema Definition (with optional presentation)
A Schema Definition is consisting of a
- XML field definition (mandatory)
This is a list of fields with their types that make up the document body. (Internally this field definition gets dynamically compiled into a native class with according getter & setter properties for high efficient access via expression formulas…)
Optionally also field computation and validation formula expressions (see below) could be specified.
Example:
<?xml version="1.0" encoding="utf-8"?>
<form name="CUST-MEMB" version="1" alternatename="CustomerMembership">
<validations>
<rule id="R17C41" desc="No 'Prop1' specified">{not string.IsNullOrEmpty(d.Prop1)}</rule>
</validations>
<field name="Title" type="TEXT" calc-formula="d.Title"/>
<field name="Prop1" type="TEXT"/>
<field name="Prop2" type="TEXT"/>
</form>
- HTML, CSS form presentation (optional)
A HTML based representation of a form to be used in an UI to visualize the field contents of a document.
A Schema Definition is put into effect by uploading the (up to three) artifact(s) per schema in a running application instance using the web API. (Internally the schema is then immediately getting dynamically compiled into a native class with according getter & setter properties for high efficient access via expression formulas…)
While technically not exclusively required, a Schema Definition is typically defined with the dedicated tool like Tlabs.Meta.Bench.
Computed Field Values
Each field listed with a schema can optionally have a calculation
formula defined.
Fields with a calculation formula attached work like normal fields, but
whenever the fields of a document body are getting updated (e.g. by
sending new field values per API) the fields with a calculation formula
are subsequently overridden with the result of their computed value.
When computed fields are defined with the Tlabs.Meta.Bench we have basically two option:
Placing the field like other normal field in the visible form area. By marking the field as computed with **@Field()** directive the cell contents is giving the fields calculation formula:

(With out the additional **@Control\_Computed()** directive the field would be editable and also computed after submitting the input…)
To define an invisible computed field a **@HEADRER\_FIELDS()** directive must be placed somewhere outside the visible form area. Any **@Field()** definitions in the same column below would define invisible (and optionally computed) fields:

The calculation expression of a computed field allows to access any other field in the document body with the notation:
d.{field-name}. Additionally any functions from the Tlabs.lib default or custom defined library are also available.
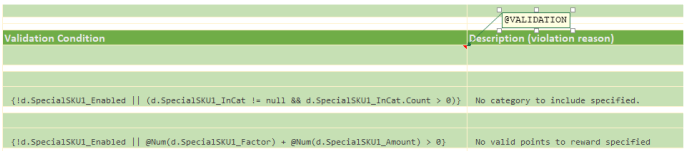
Document Validation
To enhance the quality and consistency of the data being kept in a document entity, optional document validation formulas could be specified with a document schema. These validation formulas are evaluated immediately after all fields of a document body have been updated. (Computed fields only get calculated after the validation succeeded.)
All validation expressions must result into a boolean true value to succeed else a validation error is generated.